As part of my Master’s degree, I took a Robotics independent study class in my last semester. After 4 years of undergrad and one semester of grad school, I finally got to explore my own completely independent project over the course of a 3 month semester (this was all in early 2017, I’m just getting around to posting about it). It was a ton of fun. Getting to build my own simulation, implementing and running my agent, and quantifying my results was a great way to cap off grad school.
There were a few lessons learned in that process, but the biggest one was probably “write your own damn code.” I spent too long trying to get other, far more in depth, reinforcement learning frameworks to work on my tiny little laptop (4 gb of RAM, no linux) in languages I wasn’t familiar with. Basically, when you’re prototyping a new project, don’t hesitate to start from scratch and hammer out your own implementations of things, especially if you just want to get the ball rolling. But I’m getting ahead of myself here, let me start from the top.
The idea is as follows: see if we can use reinforcement learning to teach a spacecraft to avoid some arbitrary obstacles during descent and landing on some extraterrestrial object.
Why bother with this? Smarter spacecraft are essential to building up any future space infrastructure, and entry, descent, landing (EDL) is one of the highest risk phases of any mission. For far off spacecraft that have communication delays on the order of minutes, you want to make sure that the spacecraft has enough “intelligence” to avoid problems if there is an unexpected change in trajectory. In the longer term, you also want spacecraft that can scan the surface of a planet, find a reasonable landing zone, and navigate to it successfully on their own.
The environment
I went with a simplified dynamics model on this one. I wanted to explore the actual obstacle avoidance, which would happen at altitudes <1 km on a planet like Mars. As a result, using full 2 body problem equations is kind of overkill. It is computationally far more sensible to use the Newtonian mechanics shown below:
![]()
where gm is the gravitational acceleration on Mars, 3.71 m/s2, FT is mass specific thrust, and eT is thrust direction. Of course, using reinforcement learning requires that the physics here be modeled as a Markov Decision Process (MDP). This basically means that integrating the physics shown above is the state transition equation, and state action pairs are defined by the spacecraft position and the thrust direction, which get fed into the numerical integrator (Runge Kutta 4th order).
The agent
I implemented a Q learning agent in this environment. Q learning is known as a “model free” reinforcement learning method. In essence, Q learning agents can learn the best action in a domain without actually building a map of that domain, and they can also assess the utility of their current state by “looking ahead” and looking at the reward associated with transition to another state (Watkins, Dayan). Coming up with the reward function was tricky, it is hard to guarantee convergence in a reasonable amount of time.
The plots
Enough context, on to the pretty pictures!
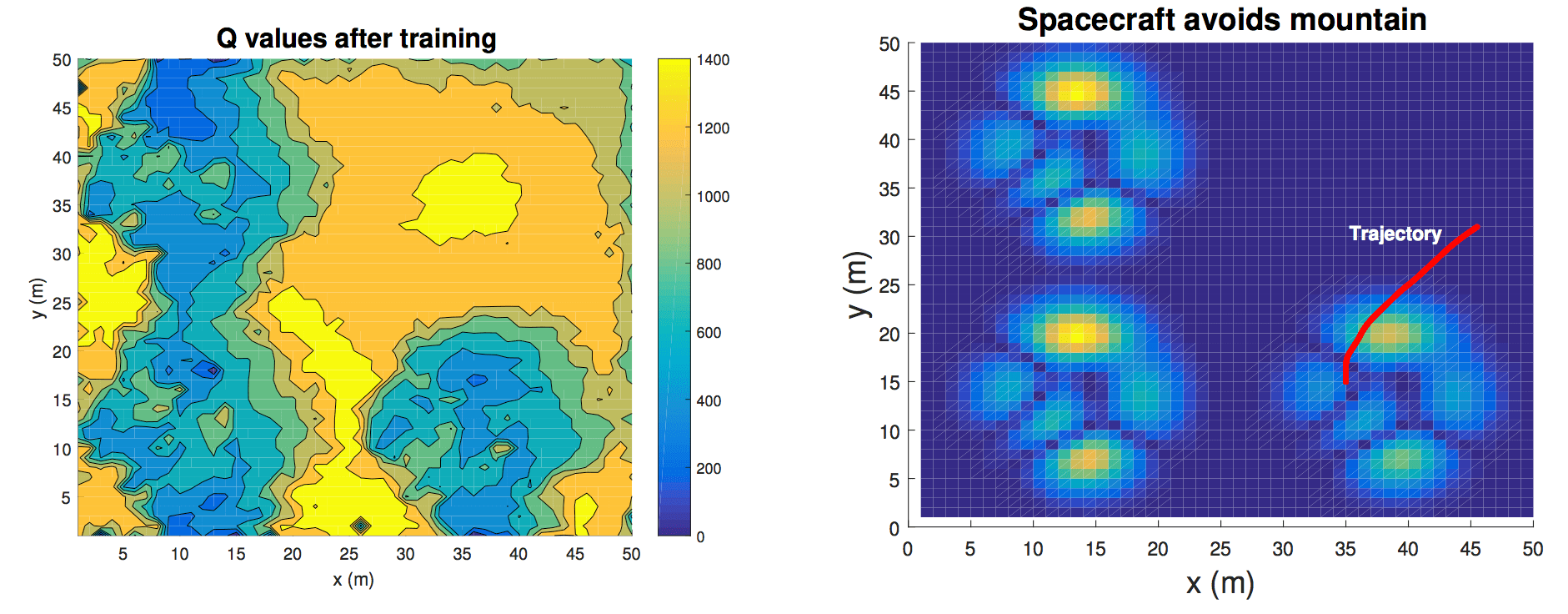
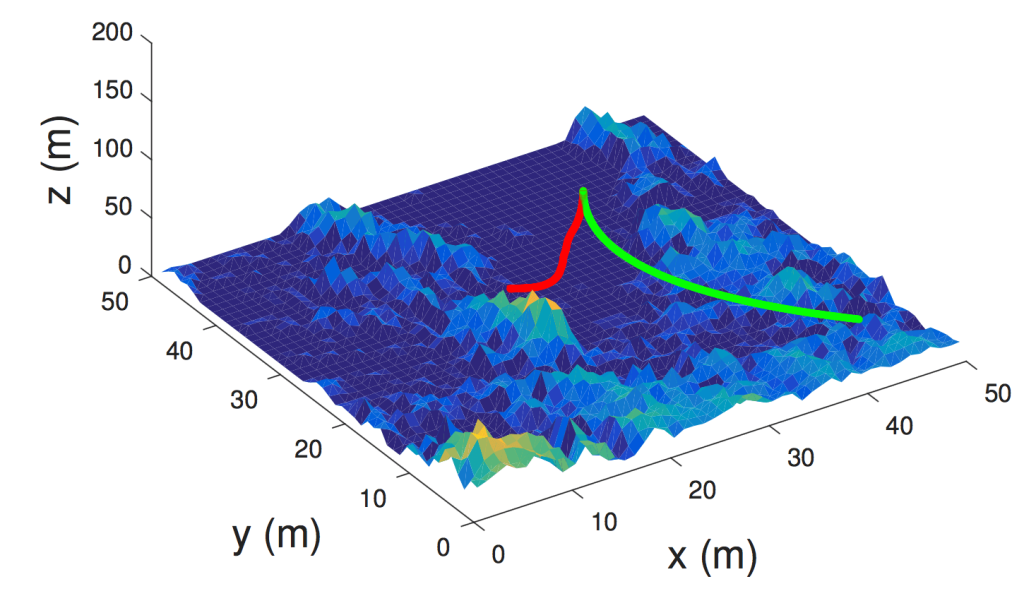
First, we can see that after 5000 training episodes, the Q learning agent has the right “reward” behavior. The plot on the left shows that terrain without mountains or obstacles has the highest Q value, which indicates a high reward. The plot on the right shows where the actual obstacles lie, and also shows a sample trajectory where the spacecraft avoids a mountain (via thrusting about the x, y, or z axis) and lands in a flat region. The terrain here is a bit boring; it is a procedurally generated map with 3 sets of big peaks.
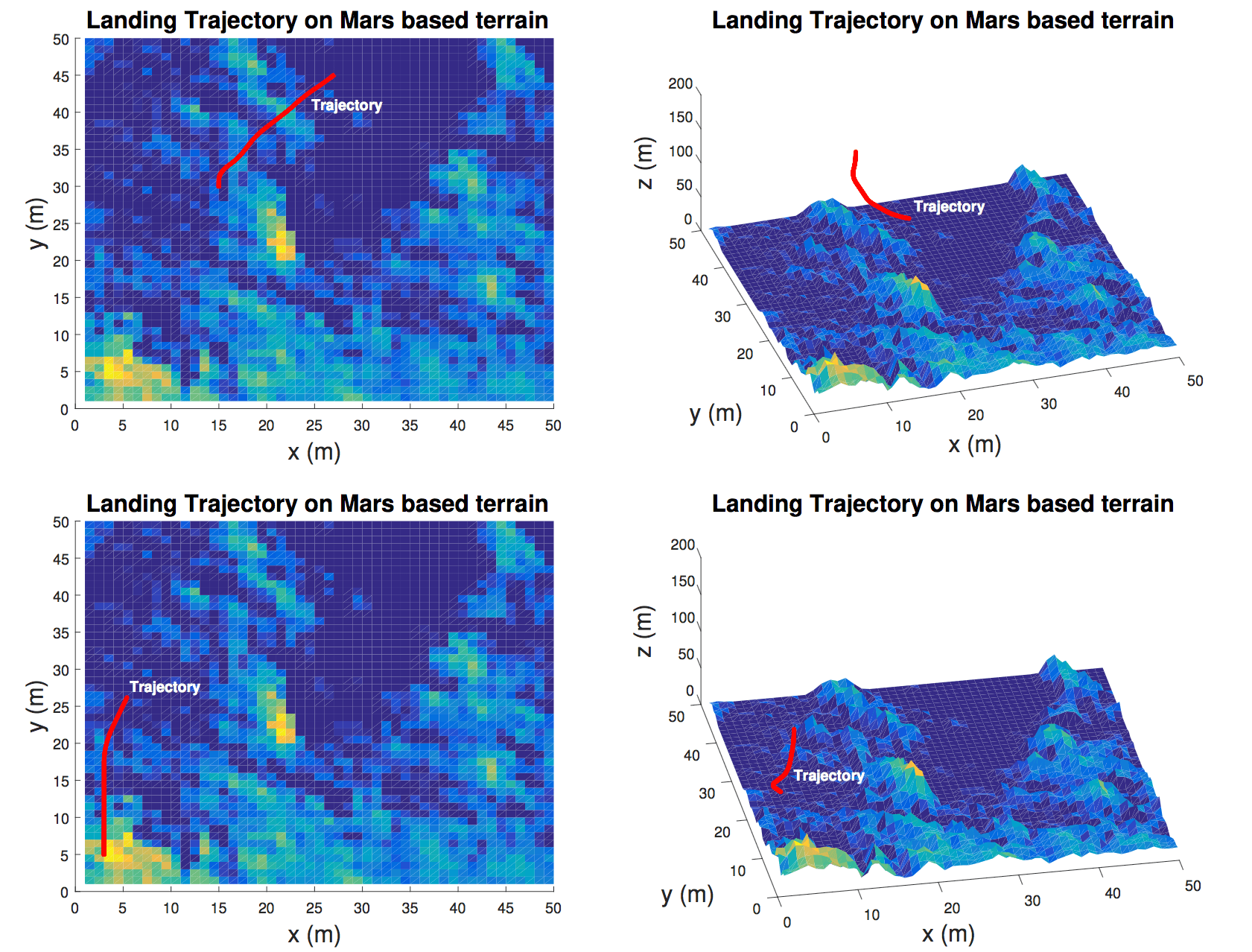
The plots above show the agent avoiding obstacles on actual Martian terrain adapted from imagery captured by the HiRISE spacecraft in orbit around Mars. I used 5000 training episodes again, and you can see the agent making a relatively sharp right turn in the lower plot to avoid surface obstacles.

In order to compare my approach, I devised a greedy policy that would basically send a thrust command pointing away from the largest obstacle within 15 m of the spacecraft at any point. This models a sensor based reactive approach to obstacle avoidance, and keeps with the tradition of comparing algorithms to the standard “greedy algorithm” in CS.
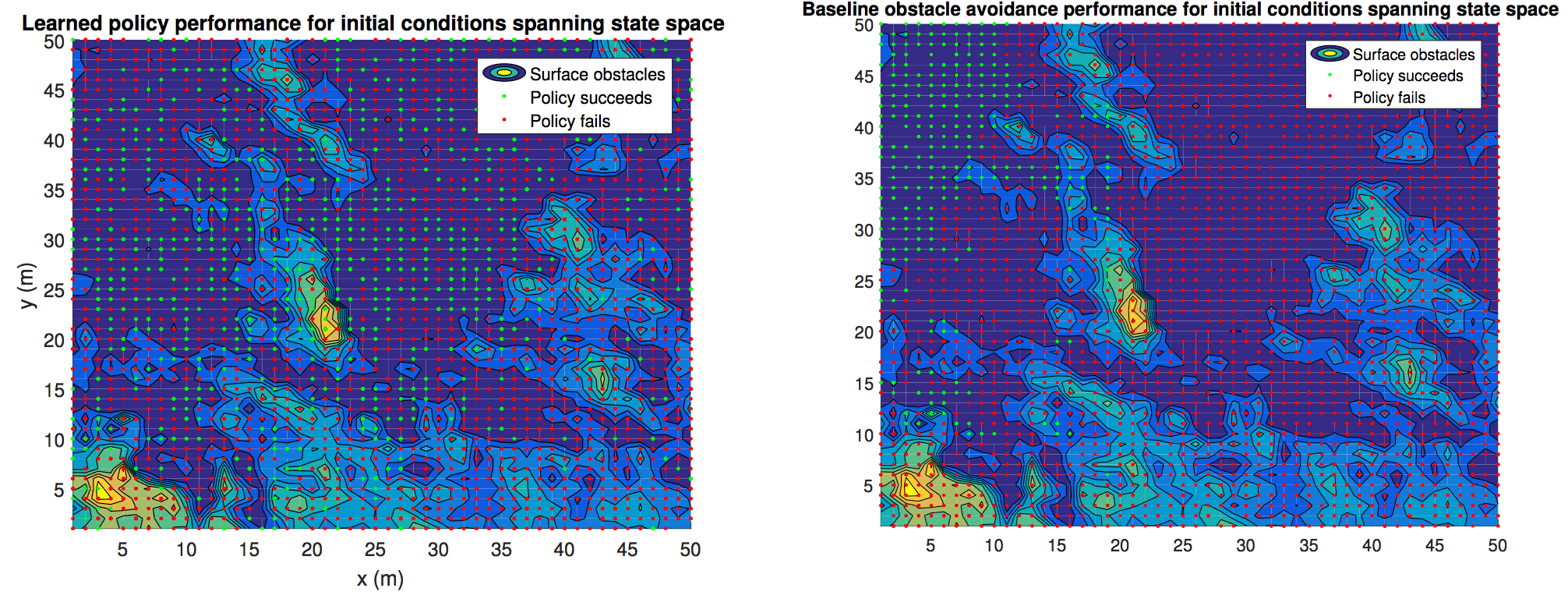
As the plots above show, generally the Q learning policy is more successful. What is also interesting is that Q learning succeeds throughout the state space – it has a much better distribution of successful initial conditions than the greedy policy.
Wrap up
I had a ton of fun with this project. It went a long way towards convincing me that research can be pretty fun. I mentioned earlier that “write your own damn code” was one of the bigger lessons learned out of this whole adventure. Honestly though, the biggest lesson learned was how many things I could have improved or done differently. Maybe I’ll get around to implementing some of it in the near future. Till then.
References
C. J. Watkins and P. Dayan. Q-learning. Machine learning, 8(3-4):279–292, 1992.

Leave a comment